
INTELIGENCIA ARTIFICIAL:
Machine Learning y Deep Learning
Parecidos pero no Iguales
Texto: Álvaro Saavedra
IBM Industry Business Development, Banking & F. Markets
Fotografía: Cortesía Google Images
Hace bien poco, en una conversación informal entre compañeros de trabajo, me di cuenta de que muchas veces en tecnología (y también en otras áreas…) utilizamos términos que no por repetidos, somos capaces de entender, y es más, que nos cuesta mucho explicar.
Dos de esos términos que más suenan asociados a inteligencia artificial son machine learning (https://en.wikipedia.org/wiki/Machine_learning) y deep learning (https://en.wikipedia.org/wiki/Deep_learning). Aunque ambos tienen su traducción en castellano (aprendizaje automático y aprendizaje profundo), casi siempre se utiliza la denominación en inglés. Son dos formas de inteligencia artificial, parecidas pero no iguales.

INTELIGENCIA ARTIFICIAL. ¿Cúal es la diferencia? Básicamente, el método de aprendizaje. El deep learning es más complejo y también más sofisticado. Es también más autónomo, lo que quiere decir que una vez programado el sistema, la intervención del ser humano es menor.
Pero, para explicarlo, utilicemos un ejemplo que todos podamos entender:
Pensemos en una persona a la que conocemos a la perfección, alguien a quien reconoceríamos simplemente por un gesto, la forma de andar o la silueta, incluso aunque estuviera disfrazado, sin ni siquiera ver su cara. Por ejemplo, tomemos a nuestro hermano, padre o madre. Ahora pensemos que tuviéramos que buscar e identificar a esa persona entre otras miles. Si fuéramos nosotros mismos los que buscáramos, seguramente en más o menos poco tiempo lo habríamos localizado sin lugar a fallo.
Ahora bien, ¿que pasaría si tuviéramos que enseñar a alguien como encontrarlo? Podríamos dar a esa persona multitud de detalles, datos que consideraríamos vitales e incluso pasar horas dándole información adicional seguramente no necesaria, pero… ¿quién creéis que reconocería más rápido y con una mayor probabilidad de acierto a quien estamos buscando? La respuesta parece clara, ¿no?
El motivo de que nuestra capacidad de reconocimiento en este ejemplo sea mucho mayor, es que nuestro cerebro ha estado años recogiendo millones de muestras de esa persona a partir de las cuales ha desarrollado la capacidad de identificar únicamente aquellos datos cruciales que necesita. Por mucho que quisiéramos explicar a un tercero qué detalles tendría que buscar, éste tendría que ir sujeto por sujeto, evaluando si cumple o no con cada uno de los patrones de búsqueda. Tomándose mucho más tiempo, equivocándose varias veces y haciendo necesario reconsiderar constantemente la combinación de los datos que le habíamos dado inicialmente.
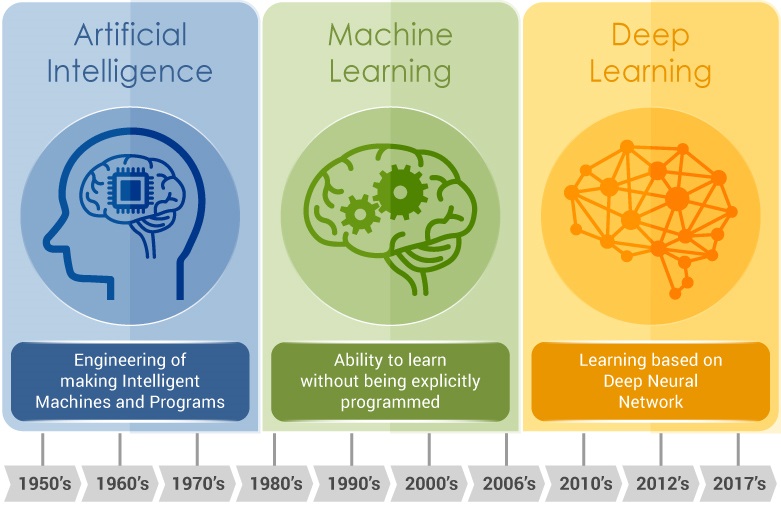
Por ahí va la diferencia entre el Machine Learning y el Deep Learning.
En el primero, al sistema se le proporciona a un algoritmo un conjunto de reglas para que las aplique cuando se encuentre con los datos pertinentes y el sistema eso sí, tiene la capacidad de adaptar dichas reglas y crear otras nuevas para mejorar su tasa de acierto.

La mayor limitación del machine learning consiste precisamente en que aquellas características que son objeto de análisis estadístico deben ser previamente especificadas por el programador de forma manual.
Si el programa sólo opera en un entorno controlado, las variables son relativamente reducidas. Sin embargo, cuando trasladamos esta tecnología a entornos reales de la vida cotidiana, comienzan a surgir dificultades, como en el ejemplo del reconocimiento de una persona que mencionaba anteriormente. Aunque a priori nos pudiera parecer acotable, en la práctica la más sutil variación, como una visibilidad parcial o reducida hace que el sistema no sea fiable.
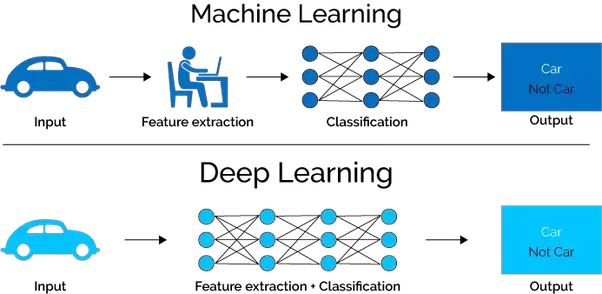 El Deep Learning es la respuesta a este problema. En el Deep Learning el aprendizaje se hace a un nivel más detallado, en este caso el entrenamiento va por capas o unidades neuronales. Basicamente. el funcionamiento de estos algoritmos trata de imitar al del cerebro. En el Deep Learning cada capa procesa la información y arroja un resultado que se revela en forma de ponderación. Lo que hace este sistema es reducir el margen de error y, por tanto, aumentar la precisión de las conclusiones. ¿Cómo se entrena? Introduciendo una cantidad exorbitante de información, para que sus ponderaciones se vayan puliendo ellas solas. Esto último es precisamente una de sus principales desventajas: necesita un número muy alto de datos para que el algoritmo tome decisiones correctas.
El Deep Learning es la respuesta a este problema. En el Deep Learning el aprendizaje se hace a un nivel más detallado, en este caso el entrenamiento va por capas o unidades neuronales. Basicamente. el funcionamiento de estos algoritmos trata de imitar al del cerebro. En el Deep Learning cada capa procesa la información y arroja un resultado que se revela en forma de ponderación. Lo que hace este sistema es reducir el margen de error y, por tanto, aumentar la precisión de las conclusiones. ¿Cómo se entrena? Introduciendo una cantidad exorbitante de información, para que sus ponderaciones se vayan puliendo ellas solas. Esto último es precisamente una de sus principales desventajas: necesita un número muy alto de datos para que el algoritmo tome decisiones correctas.
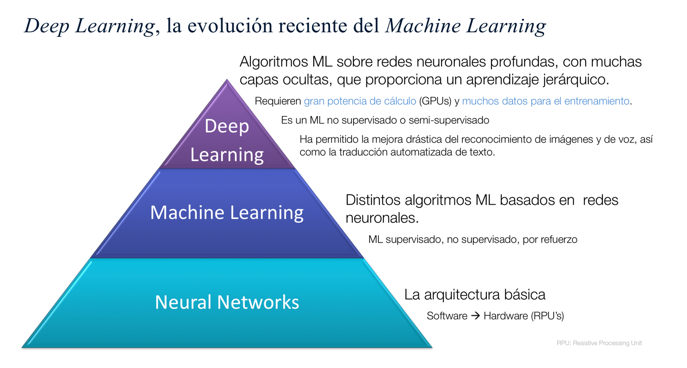
Deep Learning, la evolución reciente del Machine Learning.
Hace poco más de un mes, IBM ha lanzado el “Deep Learning as a Service” con el objetivo de que la inteligencia artificial avanzada sea más accesible para los usuarios de todo el mundo
Sin lugar a dudas, tecnologías como la inteligencia artificial y el Deep Learning están cambiando nuestra forma de aprender, de relacionarnos y de entender el mundo de forma radical.

Álvaro Saavedra López. Industry Business Development, Banking & F. Markets. Experto de Soluciones Riesgos y Cumplimiento de IBM.
Álvaro Saavedra, es actualmente responsable del negocio de Soluciones Cognitivas de IBM para Banca en España, Portugal, Grecia e Israel, tras una carrera de más de dos décadas en el sector financiero y bancario en las áreas de auditoria, control de gestión y riesgos. Profesor, ponente y consultor para distintas entidades académicas y de negocios: Instituto de Estudios Bursátiles (IEB), ESADE, Escuela Estudios Cooperativos (UCM), IMADE, META10, Global Group, BAI Centro de Estudios, CECA, Denzi E.T.T., ECA DC Formación, entre otras. Saavedra, posee una Licenciatura en CC. Económicas y Empresariales de la Universidad Complutense de Madrid, un MBA Internacional de ESDEN/IEDE Escuela de Negocios en Madrid, y un Máster en Dirección de Empresas de Participación de la Universidad Complutense de Madrid.



